Essa é uma parte do livro Introdução à Web Semântica que escrevi. Como é um livro de 2017, então, pode ter alguns pontos desatualizados. Eu não editei para postar aqui. Mas acho que o grande contexto continua o mesmo.
É interessante que hoje, organizar, categorizar, curar e produzir conteúdo e informação é algo tão comum e necessário que esse assunto se torna relevante novamente. Grande parte das pessoas "comuns", não tomam tempo ou não veem importância em fazer qualquer tipo de filtro ou curadoria do conteúdo que absorvem todos os dias.
Estamos avançando para um cenário onde basicamente o fluxo de informação vai fluir e ficar conectado cada vez mais, alimentando não só as redes sociais, mas diversas outras fontes de serviços. Não vai ser fácil criar mecanismos para controlar esse fluxo, mantendo o mínimo de organização informações que ficarão guardados ou relacionadas nesses serviços.
Pode ser até utópico falar sobre esse assunto agora, até por que a Web 3 ainda parece ser algo meio longe. Mesmo assim, entender um pouco sobre como a informação é conectada, relacionada e consumida é importante.
Produzindo informação como nunca
A humanidade nunca produziu tanto conteúdo como hoje. Um artigo escrito em 2010 para o TechCrunch, Eric Schmidt citou que a cada dois dias, a humanidade produzia mais conteúdo do que se produzia em 2003. Em outro artigo na Science Daily - site sobre ciência e tecnologia - fala que 90% dos dados que existem no mundo foram criados nos últimos entre 2011 e 2013. Isso quer dizer que a humanidade criou 90% dos dados do mundo no período de dois anos. Eu não sei você, mas fico bastante impressionado com uma informação dessa.
Gerar, ler e interpretar dados faz parte da nossa vida cotidiana e é tão natural como dormir. O mundo é movido por dados gerados no mercado financeiro. Até a decisão de sair ou não com o seu guarda-chuva é baseado em dados meteorológicos que a moça do tempo informou no Jornal da noite anterior. Você, como pessoa, gera um enorme números de dados todos os dias.
Nos últimos anos eu fiquei viciado em medir alguns dados relacionados à minha saúde. Eu precisava perder peso rápido e queria conhecer mais meu corpo e meus hábitos. Na época eu comprei um sensor chamado FitBit One - que nem existe mais hoje - que me ajudou a medir a quantidade de passos que ando diariamente, qualidade do meu sono (medindo quanto tempo dormi, quantas vezes acordei durante a noite, quanto tempo fiquei em sono profundo), quantidade de calorias ingeridas, calorias perdidas durante o dia, quantidade de quilômetros que percorri, medição de massa magra, massa gorda, medidas do corpo e um monte de outras coisas. Tudo o que qualquer wearable faz hoje.
Já na internet, a geração de dados dados é constante e ininterrupta. Toda vez que entramos em um site, geramos dados como número de páginas visitadas, tempo de permanência em cada página, links clicados, qual o seu browser, sistema operacional, tamanho do monitor, IP e etc. Todos esses dados, depois de processados, geram uma massa de informações que ajudarão a tomar decisões importantes.
A internet guarda dados de empresas e governos. Guarda dados científicos, dados sobre acontecimentos históricos, notícias de última hora, e principalmente dados pessoais. Você pode citar uma série de outros exemplos aqui.
Mas tem um problema: a grande maioria desses dados não podem ser relacionados, conectados e reutilizados.
Em 1945, quando Vannevar Bush escreveu As We May Think, um dos seus questionamentos era que a humanidade produzia conteúdo a todo momento, mas esse conteúdo não podia ser consultado de maneira fácil, e principalmente, não podia ser relacionado.
Relacionar os dados é um passo para você transformar todos esses bits e bytes em algo mais importante: informação. Mas como fazemos isso?
Transformando dados em informação
A palavra dado vem de uma única palavra latina datum, que significa "algo dado". Com o passar dos anos, esse significado mudou e hoje a palavra "dado" é como o plural de "datum".
Dados são a matéria prima da informação. Um dado, sozinho, raramente traz algum sentido ou significado de forma que possamos usá-lo de forma útil. Dados são simplesmente fatos de pedaços de informação, mas não informação em si. Dado é algo cru, que precisa ser processado, organizado, interpretado ou estruturado para que possamos extrair algo realmente útil e que tenha significado, resultando em informação.
Informação é o resultado do tratamento e do relacionamento desses dados. O dado, por si só não é nada.
Dados se tornam mais poderosos quando relacionamos com outros dados. Em uma apresentação no TED, Hans Rosling, mostra como os dados podem nos dar informações importantes sobre o desenvolvimento humano.
Imagine se todos os órgãos governamentais, ongs e outras instituições disponibilizassem seus dados para que pesquisadores como Hans Rosling pudessem organizar e extrair informações importantes para o mundo inteiro. O próprio Hans comenta em seu vídeo que os insights mais importantes estão presos em bancos de dados, sendo vendidos em vez de disponibilizados de graça, em formatos incompatíveis em vez de serem acessíveis por qualquer um.
Suponha que temos acesso aos dados de uma fonte segura, que possamos tratá-los, interpretá-los e estruturá-los de forma que pudéssemos extrair facilmente essas informações, como você organizaria essa massa gigante de dados?
Como organizamos informação?
Primeiro, por que precisamos organizar a informação? A resposta é simples: para facilitar a consulta dessa informação.
Se geramos informação a partir de dados, essa informação será usada para algum objetivo. Toda a informação produzida, precisa ser consultada, seja por você, ser humano ou por máquinas. Quando digo máquinas, quero dizer qualquer coisa que possa ler essas informações e reutilizá-las para alcançar algum objetivo. Manja ChatGPT ou até qualquer buscador disponível hoje.
A record if it is to be useful to science, must be continuously extended, it must be stored, and above all it must be consulted. — Vannevar Bush, As We My Think
A produção desenfreada de informação não é um problema novo. Pesquisadores e estudiosos já discutiam maneiras de guardar informação de forma que ela pudesse ser consultada e principalmente relacionada a qualquer momento.
Em 1945, era comum guardar informação em microfilmes, fitas magnéticas ou em antigos discos de cera. Só em 1982 os CDs foram lançados pela Philips e pela Sony. Em 1996, sendo um adolescente, eu já tinha acesso a HDs de 3Gb. E daí pra frente guardar informação não era mais um problema sério.
Mas só guardar informação não é o suficiente. Precisamos ser capazes de encontrar a informação quando precisarmos dela. Deve ser possível relacionar diferentes formatos de informações. Logo, a forma como se organiza a informação é importante.
Existem diversas maneiras de organizar informação, alguns exemplos de organização simples que você deve usar todo dia:
- por localização;
- ordem alfabética;
- tempo;
- categorização;
- hierarquia;
Alfabeticamente
Essa forma de organizar é bem comum. Vale para organizar desde uma lista simples de palavras até um dicionário. É muito útil quando a pessoa conhece o termo a ser pesquisado. Assim ela consegue encontrar facilmente a informação. Mas se você não conhece o termo ou a palavra que procura, esse formato não é tão simples. Se você trata de vários termos de assuntos diferentes, por exemplo, fica complicado para a pessoa procurar, referenciar e relacionar toda a informação de um mesmo assunto, quando se está organizado alfabeticamente. Para organizar, por exemplo, livros pelos nomes dos autores, é uma boa forma de organização, mas para livros, cujo os termos trabalham se referenciando uns aos outros, não é algo fácil de se entender.
Por tempo
Uma forma bastante comum é organizar a informação de forma cronológica. Esse forma é muito comum quando organizamos informações históricas, porque conseguimos mostrar de forma linear os acontecimentos. Essa organização é muito comum em blogs, onde organizamos as postagens de forma que o leitor tenha acesso às postagens mais novas, para as mais antigas. O Twitter, até pouco tempo, organizava sua timeline dessa forma, mostrando os tweets mais novos e depois os mais antigos. Aliás, esse formato era muito usado por quase todas as redes sociais. Só depois que algumas das redes sociais piraram e começaram a criar algoritmos malucos para tentar organizar as atualizações da sua timeline de forma mais relevante, se baseando em diversos fatores comportamentais dos usuários.
Categorização
Esse formato é muito visto em websites, principalmente e-commerces que organizam seus produtos dentro de categorias. Essa forma é muito boa para que você consiga encontrar uma informação sempre que necessário. Você não precisa decorar o modelo de um produto, por exemplo, para encontrá-lo novamente. Basta navegar até a sua categoria e procurá-lo numa lista.
Mas falando da vida real, esse tipo de organização é vista em supermercados, lojas de roupa, lojas de música (ainda existe?) etc.
Curiosidade: Em supermercados, pelo menos nos EUA, há algumas regras para organizar os produtos nas prateleiras: as prateleiras de cima, guardam os produtos premium, dependendo da categoria, ficam os produtos mais saudáveis ou produtos locais. Já na segunda ou terceira prateleira, que é onde os magnatas dos supermercados chamam de Bull's-Eye Zone, ficam as marcas mais conhecidas e as marcas que vendem mais. Geralmente são as marcas que tem mais dinheiro para posicionar seus produtos nos lugares mais privilegiados. Nas últimas prateleiras, geralmente ficam os produtos de fabricação própria do supermercado ou produtos que fazem sucesso com as crianças. Normalmente, os produtos das últimas prateleiras tem os preços mais acessíveis.

Categorização é uma das formas mais efetivas de organizar informação exatamente por que você não precisa memorizar muita coisa para poder recuperar essa informação quando for necessário. É um formato mais amigável.
Por localização
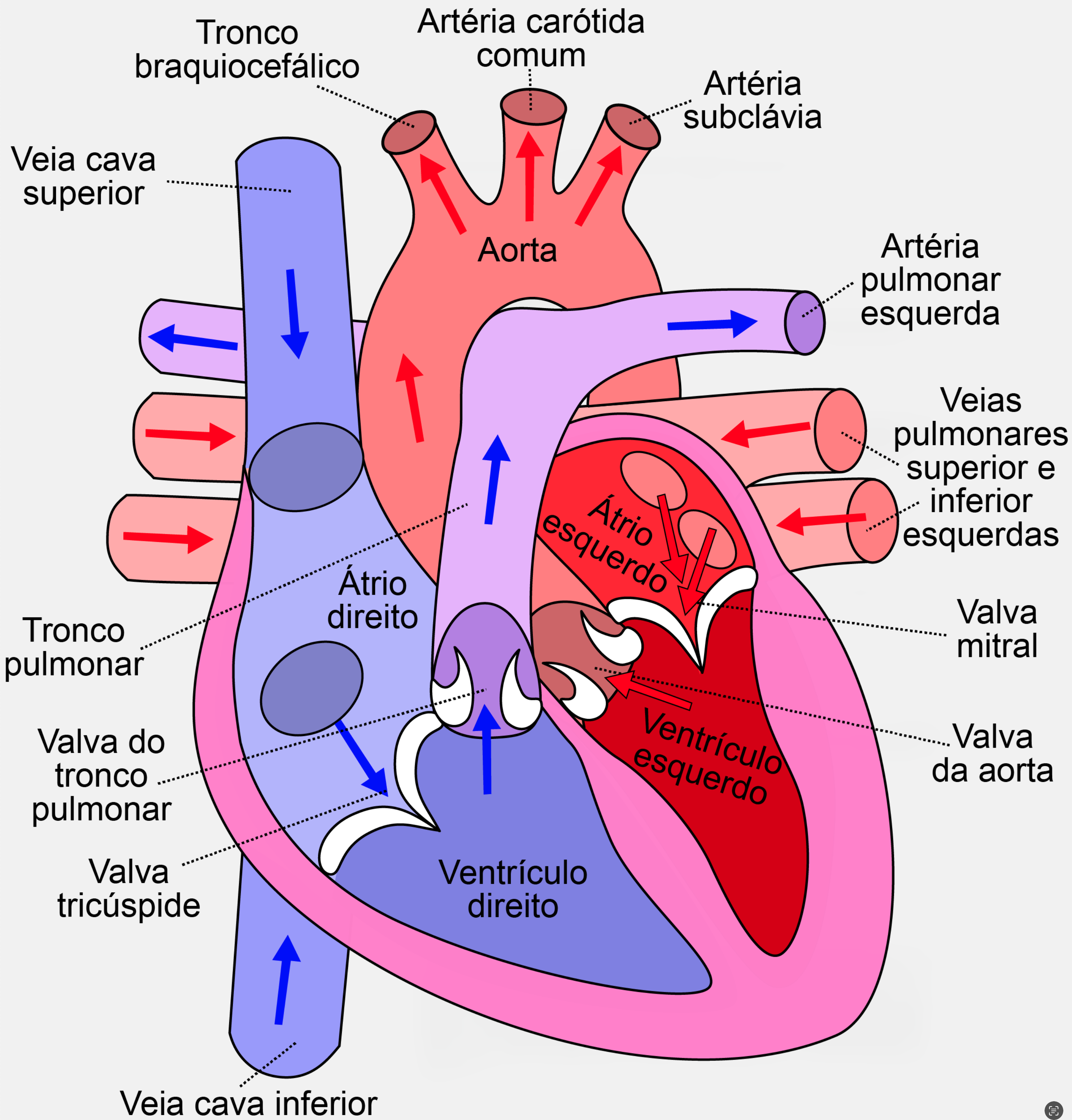
Quando organizamos por localização, geralmente usamos uma ilustração ou um diagrama para ajudar. Imagine um mapa, ou uma ilustração que mostra o que é e onde cada coisa está localizada. Tome como exemplo, esse diagrama do coração:
Outro bom exemplo é um mapa de transporte urbano:
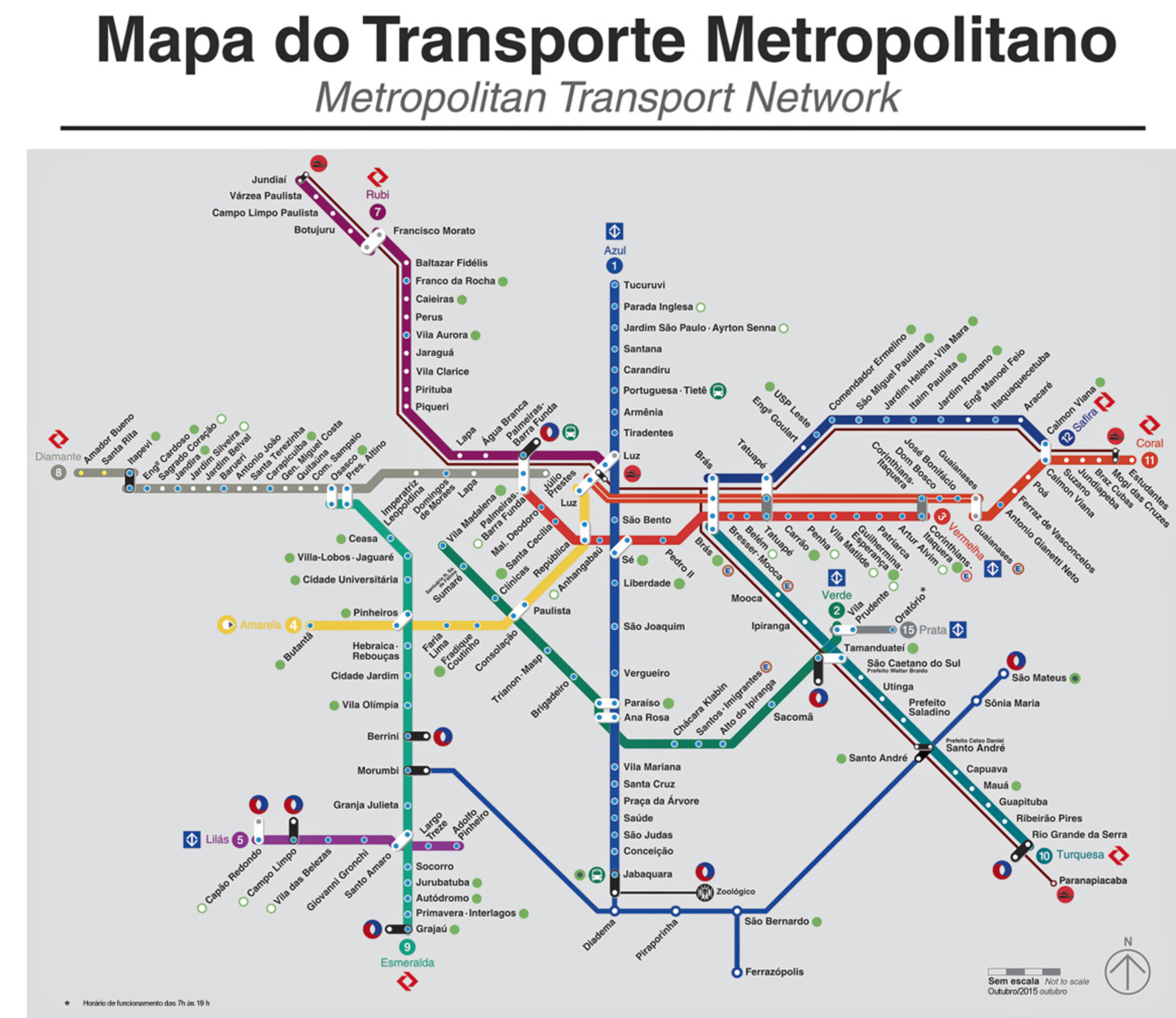
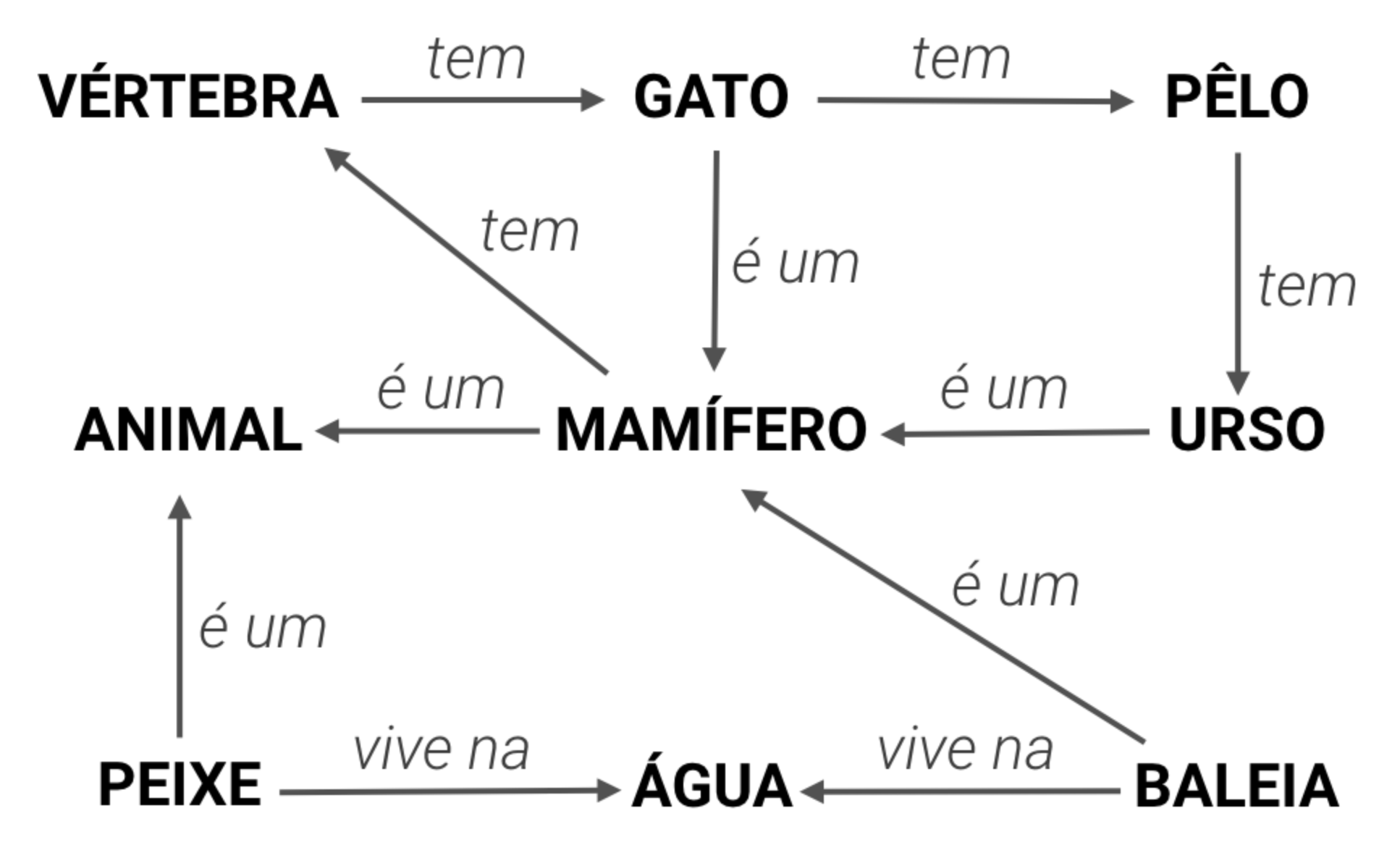
Em ambos os casos, você está relacionando a posição de alguma coisa, com o seu nome. É possível extrair desses exemplos a ordem das estações de metro, por exemplo, e quais as suas conexões. No diagrama do coração, você conhece a exata posição das partes do coração e suas relações.
Esse modo chega bastante perto do que seria as Triplas da Web Semântica, que veremos mais pra frente.
Essas são as maneias que podemos usar na vida real, com coisas físicas, por exemplo, organizando livros, documentos ou diagramas. Com a evolução da tecnologia, nós iremos organizar informações de forma mais abrangente e cada vez mais de forma associativa e relacional.
Relacionando informações
Há outro passo que precisamos considerar quando organizamos informação. A técnica utilizada para organizar a informação é importante, mas mais importante que isso é como você relaciona uma informação com outra. Vamos tentar manter o problema simples pensando em como seria possível organizar uma informação em formato de texto. Lidamos com textos todos os dias, por isso, não deve ser difícil absorver essa analogia.
Existem duas maneiras simples de fazer isso: de forma linear e de forma não linear. A forma linear é como, por exemplo, organizamos um livro. Você inicia a leitura do livro pela primeira página, avançando pelo primeiro capítulo e lê até o último. É muito difícil compreender a história iniciando a leitura pelo meio do livro. Mesmo assim, embora as informações são organizadas de forma linear, elas são organizadas (categorizadas) por capítulos e páginas, onde você consegue localizar um pedaço da história quando for necessário.
A Bíblia é um livro que usa diversas técnicas para organizar seu conteúdo. Ela é organizada mais ou menos em ordem de sua história cronológica e não na ordem em que os livros foram escritos, digo isso por que há por exemplo, indícios que o livro de Jó foi escrito antes do livro de Gênesis.
A Bíblia tem 66 livros, divididos basicamente em 2 partes, sendo o Novo Testamento e o Velho Testamento. No Velho Testamento existem 39 livros, divididos em 5 categorias: Pentateuco, Livros Históricos, Livros Poéticos, Profetas Maiores e Profetas Menores. A ideia de organizar os textos em capítulos e versículos foi criado pelos tradutores.
Já o Novo Testamento tem 27 livros, separados pelas seguintes categorias: Evangelhos, Histórico, Cartas de Paulo, Cartas Gerais e Profético.
A Bíblia é um exemplo bem completo sobre como podemos organizar uma coleção de livros. A organização em Capítulos e Versículos é útil para encontrar pedaços específicos de textos. Ainda há algumas Bíblias que têm referências no meio do texto, indicando uma relação em outra parte da história ou até em outro livro da Bíblia. Se formos olhar bem a micro-organização dos textos, chegaremos a estudar os quiasmas Bíblicos… mas esse não é o caso agora. Mas fica a dica para os mais curiosos.
Se basear por referências para organizar informações é a base da estrutura das enciclopédias. As enciclopédias, como a Bíblia, usam mais de uma técnica para organizar a informação: primeiramente as informações estão organizadas em ordem alfabética.

Era bastante comum haver uma referência a um assunto relacionado àquele que estava sendo lido, ao final do artigo, facilitando a procura por informações de um assunto de mesmo gênero.
Quando criança eu usava muito a enciclopédia Barsa, que só a minha tia tinha, para trabalhos de escola. Sempre juntava um monte de papel almaço (lembra?) e ia para casa dela tentar encontrar qualquer informação sobre o assunto a ser estudado. As enciclopédias possuem informações organizadas de forma não linear, ou seja, as informações não estão em uma ordem cronológica, como uma história, mas estão organizadas em ordem alfabética e também de forma relacional e associativa. Exemplo: quando você procura informações sobre "veículos automotores" em uma enciclopédia, ao final do texto, você pode encontrar uma série de referências dos assuntos relacionados, como, por exemplo: "motores de combustão interna", "rodas", "tipos de combustíveis", "mecânica" etc.
Essa maneira de associar uma informação com outra é mais ou menos como nosso cérebro funciona. Quando você pensa em um assunto, seu cérebro faz uma série de associações para formar uma ideia, trazer à tona uma memória ou uma lembrança. Por esse motivo, seu cérebro consegue guardar informações que podem ser recuperadas quando pensamos diretamente nelas ou quando pensamos em assuntos relacionados.
Entendendo que não é mais problema armazenar ou recuperar nossos dados, precisamos pensar em como podemos relacionar e reutilizar esses dados na internet.
Vannevar Bush e o Memex
Em 1945 foi publicado na revista Atlantic Monthly um artigo chamado As We May Think (http://www.uff.br/ppgci/editais/bushmaythink.pdf) pelo Doutor e pesquisador Vannevar Bush. No artigo ele discute um dos problemas mais difíceis da comunidade científica da época: encontrar uma forma de armazenar e recuperar o conhecimento produzido por pesquisas e investigações na área científica.
Na época, os sistemas guardavam as informações de forma hierárquica e muito linear, dificultando pesquisas e a consulta dessas informações. Vannevar Bush dizia que o nosso cérebro guarda e usa a informação de maneira fragmentada, ou seja, o pensamento humano não funciona de maneira linear, mas de forma associativa e relacional (enciclopédias, lembra?). Quando você conversa com alguém, seu cérebro faz associações buscando informações relacionadas ao assunto. Você traz à tona memórias, lembra de conversas anteriores, assuntos que estudou, informações que recebeu recentemente e assim por diante.
Mas se organizarmos a informação não de forma categorizada ou hierarquizada, mas se baseando por associações e relações, poderíamos obter mais vantagens. Tendo isso em mente ele propôs uma máquina chamada Memex.
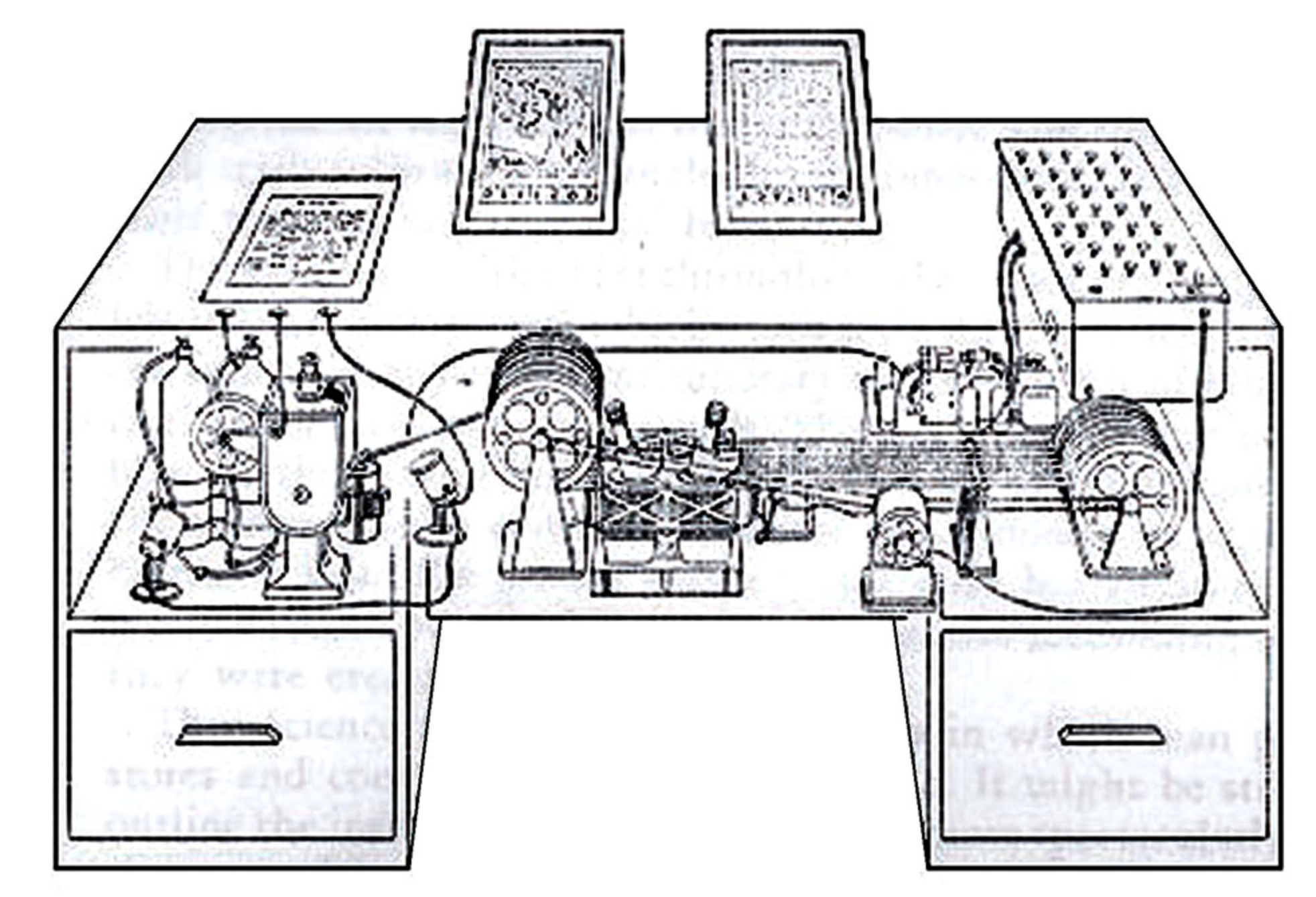
O objetivo de construir o Memex era dar a possibilidade das pessoas consultarem e relacionarem informações. Por exemplo: você poderia procurar informações sobre veículos automotores e depois relacionar esse conteúdo com informações sobre combustão interna ou qualquer outro assunto relacionado.
Na verdade, tanto naquele tempo, como ainda hoje, a forma com que lidamos com a informação ainda é bem ruim. Nós produzimos muita informação, mas não organizamos de maneira adequada, de forma que possamos relacioná-la e consultá-la. As pessoas não dão a devida atenção para os dados que elas próprias geram todos os dias e as empresas que tem informações importantes não distribuem essa informação.
O que os sistemas de busca nos dão hoje são apenas resultados, não relevantes, de termos que estão listados em websites. Você ainda precisa fazer um filtro manual pelos resultados, para encontrar o website que realmente seja relevante. Os buscadores tentam usar algoritmos para dar alguma relevância para os websites selecionados nos resultados, sendo que na verdade esperamos mais relevância no conteúdo encontrado.
Quando relacionamos uma informação com outra, nós aumentamos o contexto de relevância para o termo buscado. O Memex era uma máquina que usava a ideia de relacionamento para consultar e organizar informação. Esse “formato” de relacionar informação para facilitar a sua consulta seria conhecido mais pra frente como Hipertexto, termo cunhado pelo Ted Nelson alguns anos depois de Vannevar Bush.
Eu não estou explicando aqui qualquer coisa sobre grafos.
Douglas Engelbart e Augmenting Human Intellect
Embora o Memex nunca tenha sido construído, um cara chamado Douglas Engelbart leu o artigo As We May Think escrito pelo Vannevar Bush e se inspirou de tal forma que direcionou sua vida para colocar as ideias escritas no artigo em prática. No dia 9 de Dezembro de 1968, no Laboratório de Pesquisa de Stanford, ele apresentou para o mundo um sistema chamado NLS (oN-Line System). Isso é tão importante, que essa apresentação ficou conhecida como The Mother of All Demos. Se você assistir esse vídeo, vai entender o motivo. Nesse dia o Douglas Engelbart apresentou ao mundo o primeiro conceito de estrutura de dados e relacionamento de informação em uma espécie de computador pessoal, com direito a mouse e teclado. Talvez tenha sido a primeira vídeo conferência, onde ele usou um headset com microfone, além de um processador de texto e uma espécie de editor de código.
Douglas deu o nome desse projeto de Augmenting Human Intellect. O problema era que naquela época, para fazer um projeto de estruturação e relacionamento de dados, gastava-se alguns milhões. A ideia era que a máquina ajudasse a aumentar a capacidade da humanidade de guardar e pesquisar informação de maneira simples. Nessa apresentação, ele começa a organizar as informações em categorias e mostra como é “fácil” reutilizar e relacionar essas informações, de forma que ele consiga recuperá-las futuramente.
Ted Nelson, Projeto Xanadu e o início do Hipertexto
Embora o Douglas Engelbart tenha levado à pratica um pouco da teoria e dos estudos conhecidos até então, mostrando que toda essa ideia não era algo impossível, ainda era necessário ver algo mais palpável, global, simples de entender. Praticamente na mesma época que Engelbart mostrou pro mundo o “primeiro computador”, Ted Nelson cunhava o termo Hipertexto.
Ted Nelson tinha uma máxima que ele dizia sempre (como se eu conhecesse o cara):
”most people are fools, most authority is malignant, God does not exist, and everything is wrong.”
Sim, ele era polêmico e também era conhecido por iniciar vários projetos e nunca terminar nenhum. Faça uma pesquisa sobre ele e leia alguns de seus comentários e artigos, você vai perceber que ele é um cara bem ácido as vezes. Veja esse comentário raivoso sobre uma citação bem respeitosa que o próprio Tim Berners-Lee fez sobre ele. Tipo, bem tosco.
No one has ever paid me to be a visionary… It is vital to point out that Tim's view of hypertext (only one-way links, invisible and not allowed to overlap) is entirely different from mine (visible, unbreaking n-way links by any parties, all content legally reweavable by anyone into new documents with paths back to the originals, and transclusions as well as links-- as in Vannevar Bush's original vision). - http://hyperland.com/TBLpage
Em 1960 ele criou um projeto chamado Xanadu. Esse projeto tinha como proposta construir um sistema que o mundo pudesse usar para organizar e gerenciar dados. O ponto é não era apenas simplificar a conexão das ideias, mas representar mais claramente e corretamente a informação, tentando substituir não apenas o papel como mídia, por uma família totalmente diferente de estruturação de informação.
O pessoal envolvido no projeto, principalmente o Ted Nelson, falava que a ideia não era fazer um World Wide Web, mas sim prevenir a criação de uma!
The World Wide Web was not what we were working toward, it was what we were trying to prevent. The Web displaced our principled model with something far more raw, chaotic and short-sighted. Its one-way breaking links glorified and fetishized as "websites" those very hierarchical directories from which we sought to free users, and discarded the ideas of stable publishing, annotation, two-way connection and trackable change. - http://www.xanadu.com.au/ted/XUsurvey/xuDation.html
Xanadu consistia em uma espécie de rede mundial que permitiria que a informação fosse guardada não como arquivos separados, mas como documentos conectados. Quando você fosse escrever algum texto, por exemplo, você poderia relacionar um pedaço desse texto, com outro arquivo, que poderia estar em outro computador em algum lugar do mundo. Nos casos onde as informações tivessem diretos de copyright, os autores originais seriam pagos automaticamente pela cópia virtual de seus documentos. Eu não sei bem como ia funcionar, fica até uma tarefa para se aprofundar mais no assunto e tentar descobrir, mas seria uma espécie de pay-per-view de conteúdo.
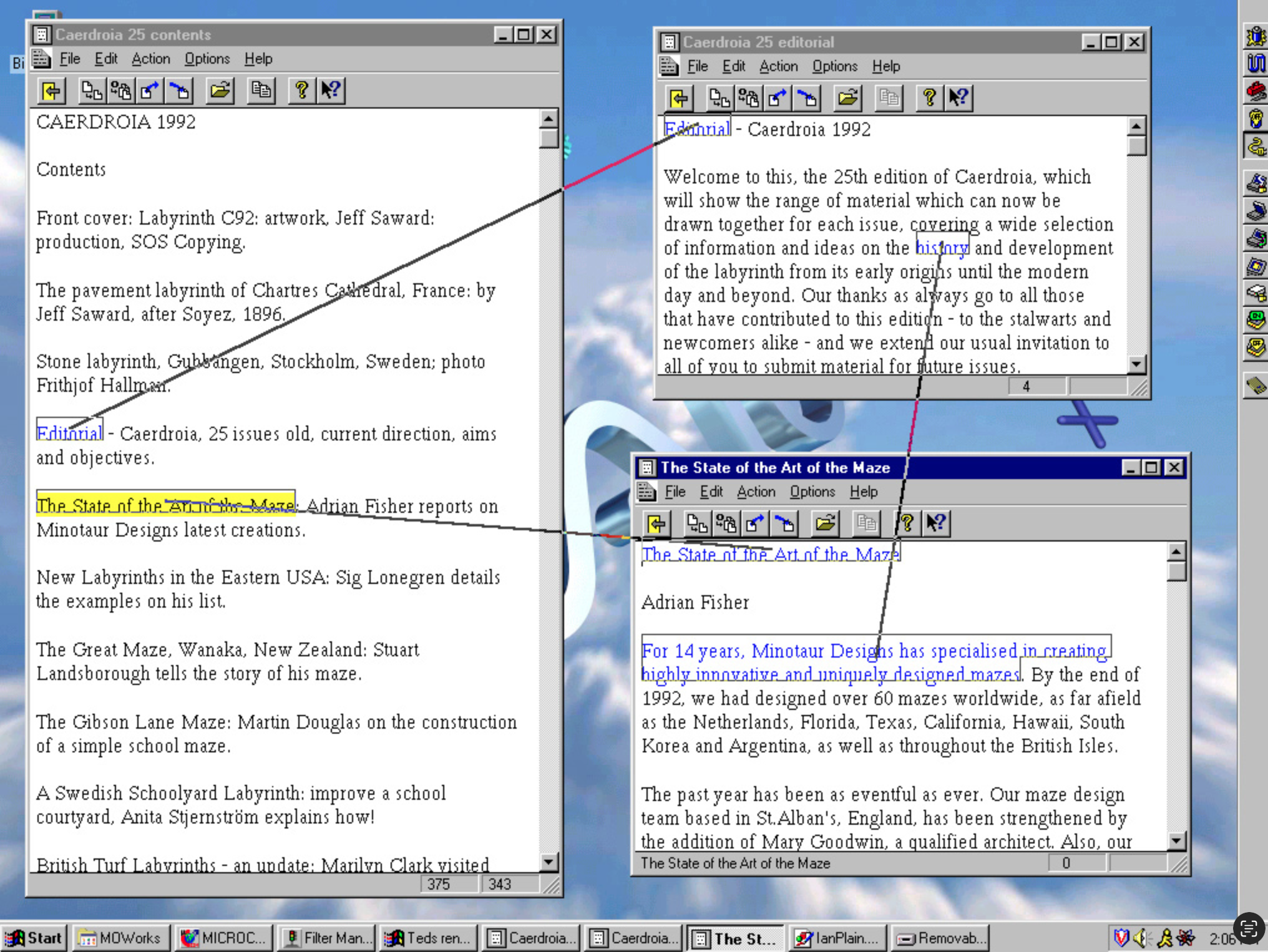
O screenshot acima é de uma demo de 1998, do conceito chamado Transpointing Windows, onde o leitor veria conexões visíveis entre o conteúdo de um documento e outro. O Projeto tinha uma estrutura de Hipertexto que eles planejaram, onde existiriam links que nunca se quebrariam, mas poderiam mudar de versão, onde documentos poderiam ser comparados lado a lado, que inclusive poderiam conter anotações dos leitores; além de ser possível ver a origem de cada uma das citações.
Por causa de problemas financeiros e várias confusões internas, o projeto não foi lançado e perdeu a oportunidade de ter sido o sistema padrão mundial de Hipertexto. O HTML ganhou e Ted Nelson não gostou muito. Ele diz que o HTML é um sistema ruim, que trata a ideia inicial (que é relacionar informação) do Hipertexto de forma trivial, com links frágeis, que quebram facilmente levando a lugar algum, que não reconhecem as mudanças das fontes originais e nem tem um sistema inteligente de pagamento de direitos de copyrights, nem princípios de multi versionamento do conteúdo ou sua reutilização.
Devo confessar que até hoje eu não consegui entender bem o projeto de Ted Nelson. Em muitas formas ele se parece ser mais complicado do que toda a ideia do HTML e da internet como ela foi concebida. Talvez, a única coisa que sobrou de bom nessa história toda foi o conceito de interconexões de informações de diversas fontes.
O Projeto Xanadu já não existe mais. Você pode ver alguns detalhes de como tudo funcionava ainda no site deles. Mas a ideia de Hipertexto, onde vários fontes de informação são relacionadas ainda persiste. Embora não seja a ideia original do Ted Nelson, acho que o HTML e a Web, como é hoje, faz um ótimo trabalho. Talvez o Projeto Xanadu nos levaria para uma internet com mais controle das empresas, menos democrática e mais inflexível. Contudo, não dá para negar que optar por um sistema mais flexível, anônimo e democrático traga uma série de problemas, como esse que estamos discutindo aqui: um padrão de organização da informação e seus relacionamentos em nível global.
Escrevi um pouco mais sobre Web 3.0, e o novo conceito de relacionamento de informação aqui: Web 3.0. O nome é clichê, mas ela já está aqui
Para ler mais
- Timeline do Hipertexto - https://en.wikipedia.org/wiki/Timeline_of_hypertext_technology
- Artigo sobre o Cérebro Humano na Super Interessante - http://super.abril.com.br/ciencia/cerebro-humano
- Know your brain - http://www.ninds.nih.gov/disorders/brain_basics/know_your_brain.htm
- http://pt.slideshare.net/dmartins/apresentao-do-artigo-as-we-may-think-vannevar-bush
- Animação do que seria o Memex - https://www.youtube.com/watch?v=c539cK58ees
- O Homem que disse não ao Tim Berners-Lee - https://www.ted.com/talks/ian_ritchie_the_day_i_turned_down_tim_berners_lee/
- The Web Before the Web - http://1997.webhistory.org/historyday/abstracts.html#doug